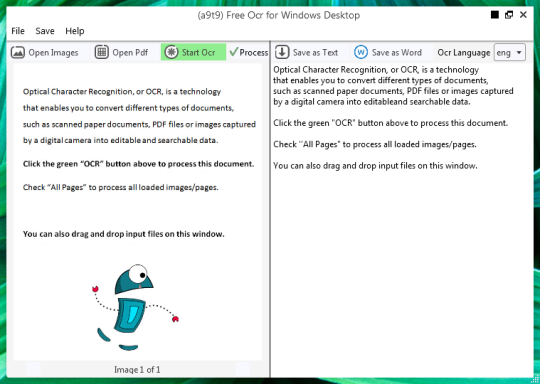
Il software libero OCR per estrarre testo da file di immagini e oggetti PDF. Un'interfaccia utente grafica (GUI) per il motore Tesseract OCR.
L'applicazione è semplice da installare e, soprattutto, libero di utilizzare, open-source e il 100% adware e spyware.
È possibile aprire un file di immagine o PDF. Il contenuto del file di origine viene visualizzato nella finestra di sinistra. Se il documento da più di una pagina, o se si apre documenti di più pagine, utilizzare le frecce in basso per passare da uno all'altro,
Si inizia l'OCR cliccando sul tasto verde OCR, e vedrete il risultato nella seconda finestra a destra. Testo di output può essere salvato come file di testo o un documento Word.
Purtroppo la qualità di conversione non è così grande. Dietro la scena si utilizza il motore OCR open-source Tesseract. La qualità varia da lingua a lingua -. In modo da andare avanti e verificare se è sufficiente per le vostre esigenze
Per gli sviluppatori di software e geek: L'OCR gratuito per gli strumenti di Windows Desktop è essenzialmente un'interfaccia utente front-end grafico (GUI) per il motore Tesseract OCR. Il codice sorgente completo è disponibile (licenza GPL).
Il motore OCR del software supporta le seguenti lingue OCR: inglese, francese, italiano, tedesco, spagnolo, portoghese brasiliano e olandese. A partire dalla versione 3 è in grado di riconoscere l'arabo, bulgaro, catalano, cinese (semplificato e tradizionale), croato, ceco, danese, olandese, inglese, tedesco (standard e sceneggiatura Fraktur), greco, finlandese, francese, ebraico, hindi, ungherese, indonesiano, italiano, giapponese, coreano, lettone, lituano, norvegese, polacco, portoghese, rumeno, russo, serbo, slovacco (standard e sceneggiatura Fraktur), sloveno, spagnolo, svedese, tagalog, tamil, tailandese, turco, ucraino e vietnamita.
I commenti non trovato