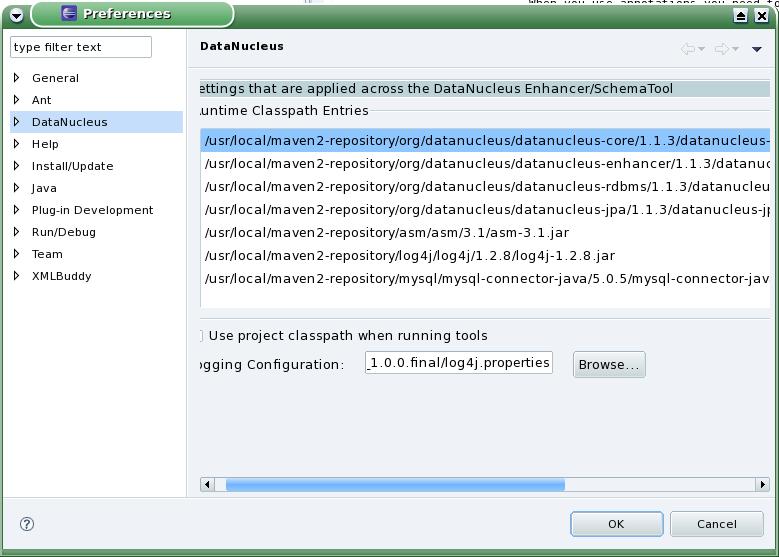
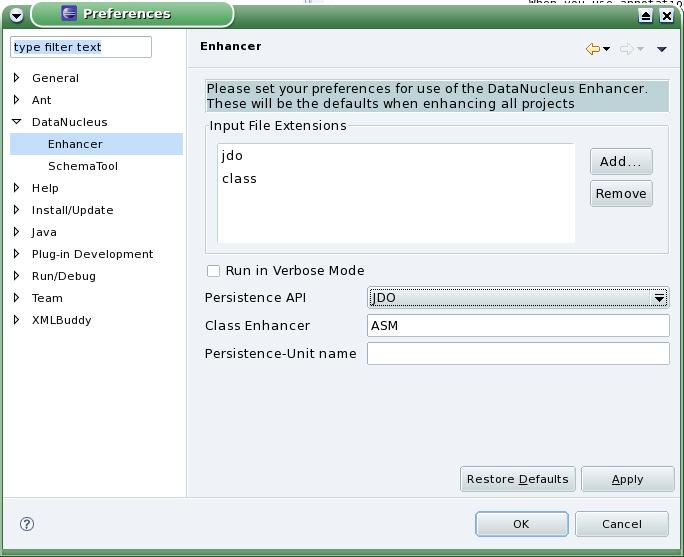
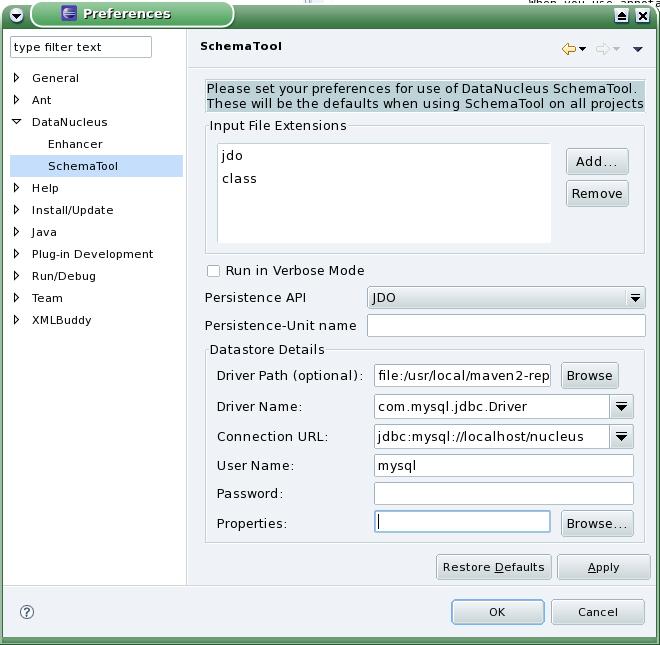
DataNucleus Access Platform è un open source, distribuito gratuitamente e software indipendente dalla piattaforma che fornisce la persistenza dei dati e il recupero di vari di archivi di dati utilizzando varie API, con una serie di query di languages.Supported API, datastore e interrogare languagesAmong le API supportate (Application Programming Interfaces), possiamo citare JDO (JDO1, JDO2, JDO2.1, JDO2.2, JDO3, JDO3.1) e JPA (JPA1, JPA2, JPA2.1). Datastore supportati includono RDBMS, db4o, LDAP, Excel, XML, NeoDatis, e JSON.
D'altra parte, DataNucleus Access Platform supporta vari linguaggi di interrogazione, tra cui JDOQL, JPQL, SQL, db4o Native, NucleusSQL, e criteri NeoDatis. Se volete JDO3.x e JPA2.0 si dovrebbe usare DataNucleus versione 4.x, e se volete JDO3.x e JPA2.1 si dovrebbe usare DataNucleus versione 3.x.Includes una grande varietà di extensionsThanks alla sua potente architettura a plugin , DataNucleus Access Platform & rsquo; s funzionalità predefinita può essere facilmente esteso attraverso le estensioni. Una grande varietà di estensioni sono disponibili per il progetto & rsquo; s sito (vedi link alla fine di questo articolo), dove si possono vedere le informazioni su ciascuno di essi.
Tra questi, possiamo citare tipi Java, livello 1/2 della cache, annotazioni, JTA localizzatore, resolver ClassLoader, store manager, gestore metadati XML, generatore di valore, di gestione JMX, meccanismi di avvio automatico, proprietà di persistenza, e la connessione di fabbrica.
Inoltre, il linguaggio di query, traduttrice stringa di identità, identità datastore, entità metadati XML resolver, convertitori di tipi, store manager, gestore membro annotazione, identità traduttore chiave, cache delle query, i metodi di query e le estensioni del gestore di classe di annotazione sono anche available.Under il cofano e operativi supportati systemsBeing scritto nel linguaggio di programmazione Java, DataNucleus è indipendente di un sistema operativo, in quanto supporta GNU / Linux, BSD, Solaris, Microsoft Windows e sistemi operativi Mac OS X. Entrambe le piattaforme di computer a 64-bit e 32-bit sono supportati in questo momento
Cosa c'è di nuovo in questa versione:.
- Auto-generare MANIFEST.MF informazioni OSGi con Maven plug fascio
- Cambia uso di StringBuffer per StringBuilder per efficienza
- Aggiungi fix a enhancement contratto per JDK1.7 + per getter utilizzando proprietà di persistenza
- Aggiungi il supporto per la valutazione in memoria di query di String.concat
- Prevedere API ripiego per la valorizzazione runtime
- Aggiungi controlli di metadati per alcuni errori di specifica chiave primaria comune
- Supporto persistenza di campi StringBuilder
- JPA: fissare i criteri FromImpl getJoins / getFetches per tornare insieme vuoto quando null
- XML: ristrutturato per consentire il potenziale di utilizzo di diverse implementazioni JAXB internamente
- XML: aggiungere il supporto per il rientro XML formattazione
- Cache: aggiornato il supporto coerenza a 3,6 +
- RDBMS: Aggiunto il supporto per gamma query in datastore per Derby, SQLServer 2012, Firebird
- RDBMS: Aggiunto il supporto per le sequenze con SQLServer 2012
- RDBMS: Aggiunto il supporto per le relazioni MN utilizzando elenchi ordinati
- RDBMS: correzioni alla creazione dello schema per le relazioni MN
- RDBMS: Aggiunto il supporto per i parametri con funzione bulk-fetch
- RDBMS: bulk-fetch aggiunto il supporto per i campi di array
- RDBMS: aggiungere capacità di disattivare bulk-fetch su una base per-query
- Geospatial: nuovo plugin comprendenti fuse spaziale / awtgeom plugins
- Geospatial: aggiunto alcuni metodi PostGIS mancanti e convalidato contro ultimo driver JDBC PostGIS
- MongoDB: migliore gestione delle parti di ordinazione / intervallo di query per correggere contributo precedente
- MongoDB: aggiornamento per usare driver più recente java
- HBase: problema fix con recupero di Enum memorizzato come numerico (ordinale)
- Varie altre correzioni di bug e miglioramenti minori
Cosa c'è di nuovo nella versione 3.3.5:
- Avvolgere ogni eccezione generata da JDOHelper.getObjectId in modo che soddisfa le specifiche JDO
- Fix per classe di carico per i validatori di proprietà per OSGi
- Coppia di correzioni per rapporto ottimista gestione
- JDO: Cambia PMF essere Serializable
- JPA: Cambia EMF e CriteriaQuery siano Serializable
- JPA: Fissare criteri CONCAT sostengono di dare forma corretta stringa JPQL
- JPA: Aggiungere il supporto per IN con i criteri query tramite CriteriaBuilder
- JPA: Aggiungere il supporto per JPQL & quot; TRATTARE & quot; nella clausola WHERE
- RDBMS: Aggiungere il supporto per recuperare massa dei campi più valori di raccolta di un candidato, quando in FetchPlan di una query (rimuove & quot; 1 + N & quot; problema)
- RDBMS: Aggiungere il supporto per SQLServer gestire JDOQL String.substring con 2 args (Daniel Dai)
- RDBMS: Aggiungere il supporto per JDOQL String.concat (Daniel Dai)
- RDBMS: Fissare al rilevamento di tipo di archiviazione secondaria necessaria per una collezione, utilizzando i metadati più
- MongoDB: Aggiungere il supporto per specificare le MongoOptions quando si crea il primo collegamento (Robin Zhang)
- Spatial: Risolti alcuni metodi PostGIS mancanti
- Varie altre correzioni di bug e miglioramenti minori
Cosa c'è di nuovo nella versione 3.2.9:
- Avvolgere ogni eccezione generata da JDOHelper.getObjectId in modo che soddisfa le specifiche JDO
- Fix per classe di carico per i validatori di proprietà per OSGi
- Coppia di correzioni per rapporto ottimista gestione
- JDO: Cambia PMF essere Serializable
- RDBMS: Aggiungere il supporto per recuperare massa dei campi più valori di raccolta di un candidato, quando in FetchPlan di una query (rimuove & quot; 1 + N & quot; problema)
- RDBMS: Aggiungere il supporto per SQLServer gestire JDOQL String.substring con 2 args (Daniel Dai)
- RDBMS: Aggiungere il supporto per JDOQL String.concat (Daniel Dai)
- RDBMS: Fissare al rilevamento di tipo di archiviazione secondaria necessaria per una collezione, utilizzando i metadati più
- MongoDB: Aggiungere il supporto per specificare le MongoOptions quando si crea il primo collegamento (Robin Zhang)
- Spatial: Risolti alcuni metodi PostGIS mancanti
- Alcune altre correzioni di bug e miglioramenti minori
Cosa c'è di nuovo nella versione 3.2.8:
- Metadata: Aggiungere livello di blocco per processo di caricamento dei metadati per assistere in ambienti multithread
- Metadata: correggere bug in OrderMetadata per ambienti multithreading
- Fissare ad alcuni potenziali problemi di avvio con ExecutionContext / ObjectProvider in ambienti multithread
- Cambio & quot; datanucleus.SerializeRead & quot ;, & quot; datanucleus.cache.collections & quot ;, & quot; datanucleus.deletionPolicy & quot ;, & quot; datanucleus.query.jdoql.allowAll & quot ;, & quot; datanucleus.query.sql.allowAll & quot; essere ignorabile sul PM / EM
- Cache: aggiornamento javax.cache sostegno a & quot; 1.0-PFD & quot; standard di
- RDBMS: Fissare al persistere di bidirezionale 1-N con Set
- RDBMS: Cambia archiviazione secondaria per essere uno per campo ed essere thread-safe
- RDBMS: Supporto per espressioni booleane più a clausola risultato JDOQL / JPQL
- RDBMS: Supporto per la persistenza di un campo serializzato in un file locale
- RDBMS: Supporto per la persistenza di un tipo di campo di file in streaming da / datastore
- RDBMS: Aggiornamento & quot; origine dati & quot; punto plugin per essere & quot; ConnectionPool & quot ;, l'aggiunta di ulteriori funzionalità
- Neo4j: supporto per la persistenza di campi mappa (Mappa, mappa)
- Neo4j: supporto per l'utilizzo di database incorporato con proprietà di configurazione forniti dall'utente
- Neo4j: supporto per l'accesso a query di Cypher sottostante per una query JDOQL / JPQL
- MongoDB: supporto per la valutazione di query di diversi metodi String in-datastore (Marcin Jurkowski)
- MongoDB: supporto per la valutazione di query di Collection.contains a-datastore (Marcin Jurkowski)
- MongoDB: fissare per il recupero di campo versione della classe (Marcin Jurkowski)
- MongoDB: supporto per letterali di query di tipo di carattere
- Alcune altre correzioni di bug e miglioramenti minori
Cosa c'è di nuovo nella versione 3.3.4:
- Metadata: Aggiungere livello di blocco per processo di caricamento dei metadati per assistere in ambienti multithread
- Metadata: correggere bug in OrderMetadata per ambienti multithreading
- Fissare ad alcuni potenziali problemi di avvio con ExecutionContext / ObjectProvider in ambienti multithread
- Cambio & quot; datanucleus.SerializeRead & quot ;, & quot; datanucleus.cache.collections & quot ;, & quot; datanucleus.deletionPolicy & quot ;, & quot; datanucleus.query.jdoql.allowAll & quot ;, & quot; datanucleus.query.sql.allowAll & quot; essere ignorabile sul PM / EM
- Cache: aggiornamento javax.cache sostegno a & quot; 1.0-PFD & quot; standard di
- JPA: Fix per metamodello Attribute.isOptional a restituire false per i campi PK
- RDBMS: Fissare al persistere di bidirezionale 1-N con Set
- RDBMS: Cambia archiviazione secondaria per essere uno per campo ed essere thread-safe
- RDBMS: Supporto per espressioni booleane più a clausola risultato JDOQL / JPQL
- RDBMS: Supporto per la persistenza di un campo serializzato in un file locale
- RDBMS: Supporto per la persistenza di un tipo di campo di file in streaming da / datastore
- RDBMS: Aggiornamento & quot; origine dati & quot; punto plugin per essere & quot; ConnectionPool & quot ;, l'aggiunta di ulteriori funzionalità
- Neo4j: supporto per la persistenza di campi mappa (Mappa, mappa)
- Neo4j: supporto per l'utilizzo di database incorporato con proprietà di configurazione forniti dall'utente
- Neo4j: supporto per l'accesso a query di Cypher sottostante per una query JDOQL / JPQL
- MongoDB: supporto per la valutazione di query di diversi metodi String in-datastore (Marcin Jurkowski)
- MongoDB: supporto per la valutazione di query di Collection.contains a-datastore (Marcin Jurkowski)
- MongoDB: fissare per il recupero di campo versione della classe (Marcin Jurkowski)
- MongoDB: supporto per letterali di query di tipo di carattere
- Varie altre correzioni di bug e miglioramenti minori
Cosa c'è di nuovo nella versione 3.2.7:
- JPA: fissare a metamodello SimpleAttributeImpl.isVersion (Adrian Ber)
- JPA: aggiungere il supporto per il multi-campo sintassi join in JPQL clausola FROM
- JPA: aggiornamento per la gestione del campo di JPQL quando trova appena primo risultato
- RDBMS: fissare per SQLServer nome schema problema (Shanyu Zhao)
- RDBMS: aggiungere il supporto per l'utilizzo di FetchPlan quando si interroga su & quot; complete-table & quot; candidato (precedente chiave primaria appena recuperato)
- RDBMS: miglioramento nel processo per determinare il nome della classe quando non sottoclassi conosciuto circa, per evitare SQL
- RDBMS: supporto per la persistenza doppio tipo in tipo SQLServer FLOAT datastore (Shuaishai Nie)
- JSON: fissare per il recupero di oggetti in query in modo che i casi di applicazione di identità hanno id assegnato
- MongoDB: Aggiungere il supporto per l'ordinazione di query in fase di elaborazione nel datastore (Marcin Jurkowski))
- Rinomina & quot; google-collezioni & quot; plugin per & quot; guava & quot;
- JDO: distribuire JDO-api 3.1-rc1
- Alcune altre correzioni di bug e miglioramenti minori
Cosa c'è di nuovo nella versione 3.3.3:
- JPA: fissare a metamodello SimpleAttributeImpl.isVersion (Adrian Ber)
- JPA: aggiungere il supporto per il multi-campo sintassi join in JPQL clausola FROM
- JPA: aggiornamento per la gestione del campo di JPQL quando trova appena primo risultato
- JPA: supporto ereditato TypeConverters (Adrian Ber)
- JPA: passano le proprietà da EMF ClassTransformer quando viene eseguito in modalità gestita
- RDBMS: fissare per SQLServer nome schema problema (Shanyu Zhao)
- RDBMS: aggiungere il supporto per l'utilizzo di FetchPlan quando si interroga su & quot; complete-table & quot; candidato (precedente chiave primaria appena recuperato)
- RDBMS: miglioramento nel processo per determinare il nome della classe quando non sottoclassi conosciuto circa, per evitare SQL
- RDBMS: supporto per la persistenza doppio tipo in tipo SQLServer FLOAT datastore (Shuaishai Nie)
- JSON: fissare per il recupero di oggetti in query in modo che i casi di applicazione di identità hanno id assegnato
- MongoDB: Aggiungere il supporto per l'ordinazione di query in fase di elaborazione nel datastore (Marcin Jurkowski))
- Rinomina & quot; google-collezioni & quot; plugin per & quot; guava & quot;
- JDO: distribuire JDO-api 3.1-rc1
- Varie altre correzioni di bug e miglioramenti minori
Cosa c'è di nuovo in versione 3.3.0 Milestone 1:
- Mapping: soddisfare eredità con (multipla ) MappedSuperclass parzialmente giù albero ma con Entity superclasse con il proprio tavolo (cioè effettivamenteMappedSubclass)
- SchemaTool: proprietà supporto di file e / o sostegni di sistema imperative persistence.xml
- Semplifica archiviazione dei metadati interno per recuperare gruppi e vincoli
- Rinomina & quot; datanucleus.metadata.validate & quot; immobili persistenza a & quot; datanucleus.metadata.xml.validate & quot;
- Aggiungi & quot; datanucleus.metadata.xml.namespaceAware & quot; per consentire il controllo sull'uso dei namespace XML
- Fix a coda di operazione per rimuovere Mappa operazioni
- Aggiungi controllo su specifica del valore discriminante per le classi astratte
- JPA: Supporto più situazioni
- JPA: corsa contro JPA 2.1 vaso API
- JPA: Supporto JPA 2.1 Index e le specifiche ForeignKey
- JPA: Supporto JPA 2.1 JPQL & quot; FUNZIONE & quot;
- JPA: Supporto JPA 2.1 Criteri UPDATE / DELETE
- JPA: Supporto JPA 2.1 DA & quot; ON & quot; in Criteri di query
- JPA: Drop supporto per DN estensioneIndex annotazione (utilizzare JPA 2.1 annotazione ora)
- RDBMS: miglioramento Generazione Schema per meglio soddisfare qualsiasi ordinamento delle classi di ingresso
- RDBMS: Generazione Schema correzione a inizializzazione ricorsiva di PK di una tabella
- RDBMS: Fix per la gestione di FK Map dove chiave / valore ha l'ereditarietà e la chiave / valore sono memorizzati in una superclasse
- RDBMS: Fissare al valore-map discriminatore gestione per oggetto incorporato
- RDBMS: aggiungere capacità di richiamare qualsiasi funzione SQL (per JPA 2.1)
- MongoDB: fissare per specificare esplicitamente il tipo di archiviazione per i tipi di wrapper primitivo
- Varie correzioni di bug e miglioramenti minori
Cosa c'è di nuovo nella versione 3.2.0:
- Fissare alla valutazione in memoria quando si utilizza una variabile che non ha valore possibile
- Sposta coda operazione per SCO a ExecutionContext in modo che possa controllare l'intero processo a livello
- Disattiva ObjectProvider pooling poiché attualmente provoca problemi quando in un ambiente altamente multithreaded
- Aggiungi controllo tentato persistenza di campi finali
- JPA: consentire all'utente l'override un datasource JNDI con un'origine dati basato su URL
- RDBMS: fissare per l'aggiornamento di massa quando si imposta i campi a NULL
- RDBMS: Cater per i campi di un tipo che hanno un TypeConverter ma nessuna mappatura definita, ricadendo al TypeConverter
- Neo4j: Sostegno alla rinfusa eliminare
- MongoDB: Sostegno alla rinfusa eliminare
- HBase: Sostegno alla rinfusa eliminare
- La versione 3.2 include le seguenti principali modifiche oltre 3.1:
- Il enhancer e ASM sono ora uniti in DataNucleus-core
- L2 cache di campi serializzati incorporati / ora di default ON
- oggetti ExecutionContext sono ora raggruppati, insieme a vari altri miglioramenti di prestazioni
- Enhancer ora include un'opzione per migliorare classi come rimovibile indipendentemente metadati
- Neo4j: ora utilizza una singola connessione per PM / EM
- Neo4j: ora supporta rinfusa eliminare
- MongoDB: ora utilizza una singola connessione per PM / EM
- MongoDB: ora supporta rinfusa eliminare
- HBase: supporta varie estensioni per i filtri di fioritura, la compressione, in-memory etc (Nicolas Seyvet)
- HBase: ora supporta rinfusa eliminare
- RDBMS: Aggiunto il supporto per il database Virtuoso (Emmanuel Poitier)
- RDBMS: aggiunto il supporto per Tomcat pool di connessioni (Marshall Reeske)
- OSGi: migliorato schierabilità a causa di restrizioni di dipendenza di versione
- JPA: validato per lavorare con JBoss 7 (grazie a Nicolas Seyvet e Scott Marlow)
- JPA: accesso di campo non a schiera si tradurrà in IllegalAccessException al posto del precedente eccezione JDO
- JPA: supporto per JPA2.1 FROM & quot; ON & quot; clausole
- JPA: il supporto per l'utilizzo di massa di persistere (), remove (), si fondono () e staccare () (passa in Raccolta o array di entità)
- JPA: supporto per JPA2.1 & quot; Generare Schema & quot; funzione
- Se un tipo è supportata persistente quindi il valore di default persistente ora (non c'è bisogno di segnare tutti i campi non-standard digitati come persistente).
- Aggiungi possibilità di disabilitare la cache L2 su un PM / EM-base dove il PMF / EMF ha permesso.
- Cache: fornisce il supporto per javax.cache v0.61
- Molti bug fixes, e dispongono di minori integrazioni.
Requisiti :
- Java 2 Standard Edition Runtime Environment
I commenti non trovato