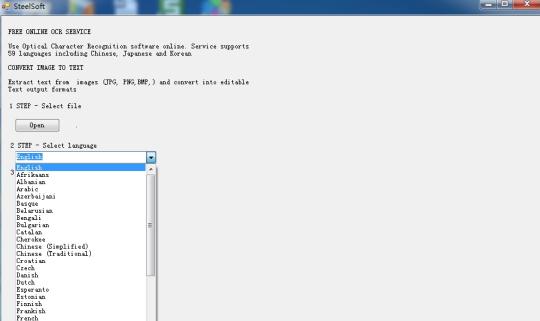
Riconoscere il testo da immagini utilizzando il motore di Tesseract OCR basato sulla tecnologia cloud.
Utilizzare il software Optical Character Recognition on-line. Service supporta 59 lingue, tra cui cinese, giapponese e coreano. Estrarre testo da immagini (JPG, PNG, BMP, TIF) e convertirli in formati di output di testo modificabili.
Si basa su tecnologia cloud, e molto famoso motore OCR (Tesseract OCR Engine), quindi c'è solo centinaia di KB di dimensione, ma può estrarre il testo in 59 lingue, dalle immagini.
Esso supporta più lingue: bulgaro, catalano, ceco, danese, olandese, inglese, finlandese, francese, tedesco, greco, ungherese, indonesiano, italiano, lettone, lituano, norvegese, polacco, portoghese, rumeno, russo, serbo, slovacco, sloveno , spagnolo, svedese, tagalog, turco, ucraino, vietnamita, ecc
Cosa c'è di nuovo in questa versione:..
La versione 5.0 include miglioramenti UE

I commenti non trovato