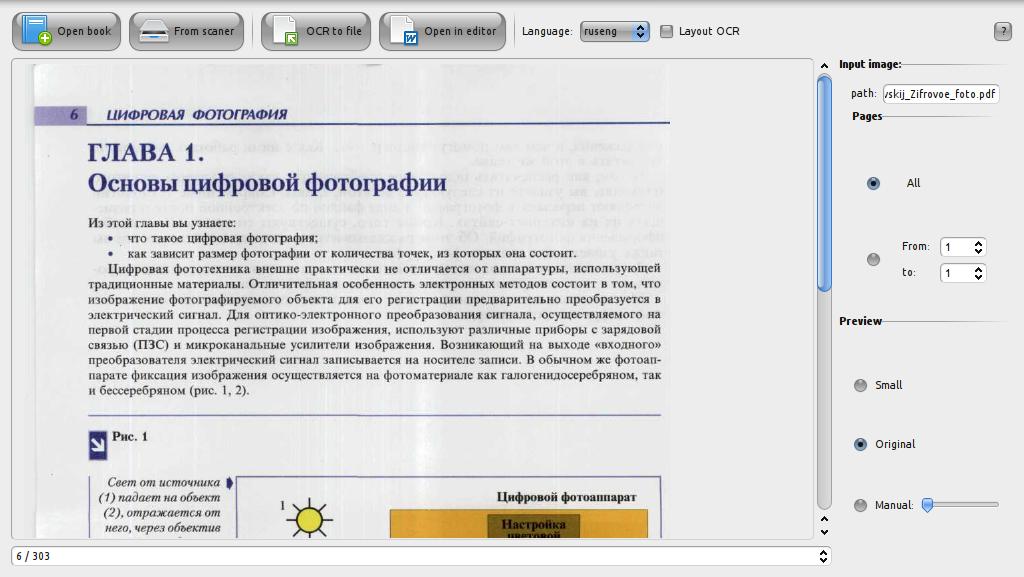
KBookocr è un sistema intelligente per il riconoscimento di documenti (sistema OCR).
Ingresso: Specificare il documento che si desidera riconoscere (djvu o pdf) + Scegliete la lingua del documento di input.
Pagine di procedere: La scansione può essere condotta di tutto il documento o un intervallo selezionato.
Formato Anteprima: Ecco alcune opzioni di anteprima (che si trova nella finestra di anteprima a sinistra):
Nativo
Piccolo
Output: i documenti in uscita possono essere salvati in formato txt (specificare la cartella che si desidera salvare) o aperti con OpenOffice.
Sulla base di: Cuneiform
Nota:. La qualità di un file di output dipende dalla qualità della fonte di ingresso e l'opera di terze parti pacchetto OCR
Cosa c'è di nuovo in questa versione:
- Una migliore integrazione KDE, meglio UI, pre-build solo per x32
Cosa c'è di nuovo nella versione 2.0:
- nuova versione principale di KBookOCR. Tutti i nuovi:
- nuova interfaccia grafica,
- sistema nuovo progetto,
- nuova integrazione con il sistema di scrittura cuneiforme,
- nuovo regime di sostegno scaner (KSane).
- E 'più stabile, più veloce rispetto alla versione 1.x
Cosa c'è di nuovo nella versione 1.4.1:
- È possibile caricare ultimo progetto e continuare a lavorare su esso.
Cosa c'è di nuovo in versione 1.4 Beta:
- Prenota pagine miniature per il riconoscimento, l'opzione di scansione in batch
Cosa c'è di nuovo nella versione 1.3:
- Nuova interfaccia grafica
I commenti non trovato