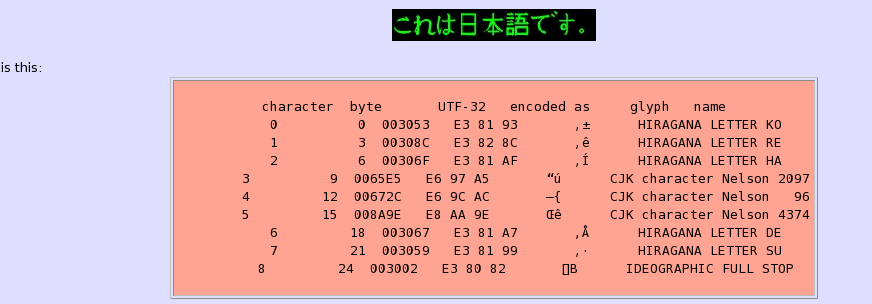
uni2ascii e ascii2uni conversione tra Unicode UTF-8 e qualsiasi di una varietà di 7-bit ASCII equivalenti tra cui: esadecimali e decimali HTML riferimenti di carattere numerico, u-fughe, esadecimale standard e esadecimale crudo.
Tali equivalenti ASCII sono utili quando si comprese il testo Unicode nei sorgente del programma, durante l'immissione del testo in programmi web in grado di gestire il set di caratteri Unicode, ma non sono a 8-bit di sicurezza, e durante il debug.
L'Unicode sfugge disponibili sono:
- HTML esadecimali riferimenti a caratteri numerici (ad esempio)
- HTML decimali riferimenti di carattere numerico (es ȳ)
- U-fughe, usati in Python (ad esempio u00e9)
- U-fughe all'interno delle BMP e U-fughe oltre il BMP, ad esempio, u00e9 ma U00010024.
- U -escapes (ad esempio U 00E9)
- U-fughe (ad esempio u00e9)
- U-fughe (ad esempio u00e9)
- U-uscite tra parentesi angolari (ad esempio)
- X-fughe (ad esempio x00E9)
- X-fughe con bretelle (ad esempio x {} 00E9)
- Esadecimale standard (ad esempio 0x00E9)
- Esadecimale Raw (ad esempio 00E9)
uni2ascii accetta una bandiera della riga di comando per determinare se generare maiuscole AF o minuscola af come cifre esadecimali da alcuni alcuni programmi accettano solo uno o l'altro. ascii2uni accetta sia.
Nel caso di uni2ascii per impostazione predefinita, solo i caratteri al di fuori della gamma ASCII vengono convertiti. Anche se i caratteri ASCII vengono convertiti, a capo vengono mantenuti a meno che la loro conversione sia esplicitamente richiesto. Caratteri di spazio sono anche conservati a meno che la conversione venga esplicitamente richiesto. Nel caso dei tre spazi non ASCII (spazio Ethiopic parola, spazio Ogham, e lo spazio ideografico), se i caratteri di spazio non vengono convertiti, questi vengono sostituiti con spazio ASCII (0x20) in modo da mantenere l'uscita all'interno del 7- ASCII bit.
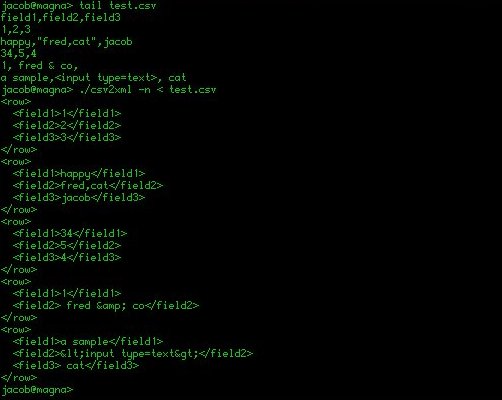
Questo pacchetto contiene quattro programmi. Il programma principale è uni2ascii. È scritto in C e deve essere compilato. uni2html.py è il predecessore di uni2ascii. Come è scritto in Python, non ha bisogno di essere compilato e dovrebbe funzionare su quasi tutti i computer attuali. uni2ascii è comunque superiore in quanto:
- Genera una più ampia gamma di formati di output.
- Si tratta di circa 20 volte più veloce.
- Gestisce ingresso nella gamma completa Unicode a 32 bit. Al contrario, uni2html gestisce solo la
Basic Multilingual Plane (Piano 0) perché attualmente Python rappresenta Unicode testo codificato internamente interi a 16 bit. Se hai testo in, diciamo, lineare B o ugaritico, è necessario uni2ascii.
Si fa un lavoro migliore di segnalazione degli errori. Se si verifica un errore nel suo input, quali mal-formato UTF-8, esso segnala la posizione dell'errore sia in termini di numero di caratteri dall'inizio del file (partendo da 0) e in termini di numero di byte dall'inizio del file (anche a partire da 0). (Conta di caratteri e il numero di byte in genere non sono la stessa da un carattere codificato UTF-8 occupa da uno a quattro byte.) I rapporti solo versione Python il conteggio dei caratteri. uni2ascii fornisce anche informazioni sulla natura dell'errore.
Il terzo programma, ascii2uni, è l'inverso di uni2ascii. Accetta il testo che contiene una varietà di rappresentazioni ASCII dei caratteri Unicode e genera Unicode UTF-8.
Il quarto programma, ascii2uni.py, legge 7-bit ASCII contenente u escape Unicode, come quello usato in Python e Tcl, e lo converte in Unicode UTF-8. E 'il programma originale di cui ascii2uni è una generalizzazione
Cosa c'è di nuovo in questa versione:.
- Corretto il bug in uni2ascii in che in alcuni casi il numero di possibilità di sostituzione era troppo alto, che fissa Debian bug # 626268.
- rattoppato per gestire la situazione in NetBSD che manca getline.
- semantica di opzione puro chiarito come la conversione di caratteri ASCII diverso spazio e nuova riga. Corretto un bug in cui questa non è stata applicata correttamente per tipi UTF8.
Cosa c'è di nuovo nella versione 4.17:
- In aggiunta a uni2ascii le seguenti conversioni dalla più vicina ascii equivalente: U 2022 proiettile a 'o', U + puntino 00B7 mezzo di periodo, U + 0085 riga successiva a Newline, separatore di linea U + 2028 a fine riga.
Cosa c'è di nuovo nella versione 4.16:
- Il formato Q funziona di nuovo in ascii2uni .
- Aggiunto U + 2033 DOUBLE PRIME ai caratteri convertiti nei loro equivalenti ascii più vicina sotto utilizzando il formato e in uni2ascii.
Cosa c'è di nuovo nella versione 4.15:
- endian.h Rinominato per u2a_endian.h di eliminare ogni contrasto con endian.h esterni.
- Rimosso copia di GNU getline da ascii2uni.c come è standard di POSIX2008.
Cosa c'è di nuovo nella versione 4.14:
- Risoluzione di un errore che ha interferito con l'uso del formato Q in uni2ascii.
- Corretto il bug in cui ascification di U + 2502 e U + 2503 aggiunge doppia citazione di uscita.
- Corretto un bug in cui -a opzione S ha generato un & quot; fabbricato tanti caratteri & quot; riga per ogni personaggio a causa lasciando in codice di debug.
Cosa c'è di nuovo nella versione 4.13:
- Corretto il bug che causava il numero eccessivo di caratteri cambiato in ASCII da segnalare.
Cosa c'è di nuovo nella versione 4.12:
- I due programmi consentono ora il nome del file di input da specificare su la riga di comando senza il reindirizzamento.
Cosa c'è di nuovo in versione 4.11:
- Questa release aggiunge il supporto per il tag & lt; XX & gt; & lt; XX & gt; e formati% uXXXX.
Cosa c'è di nuovo in versione 4.10:
- Questa release corregge un bug che rendeva l'argomento Y alla -a di ascii2uni un no-op, e corregge le pagine man e aiuto per gli argomenti Y e Q alla bandiera -a per entrambi i programmi.
- L'argomento Y è ora un errore per uni2ascii.
- Le informazioni sulla versione e azione sommari sono più informativi.
I commenti non trovato